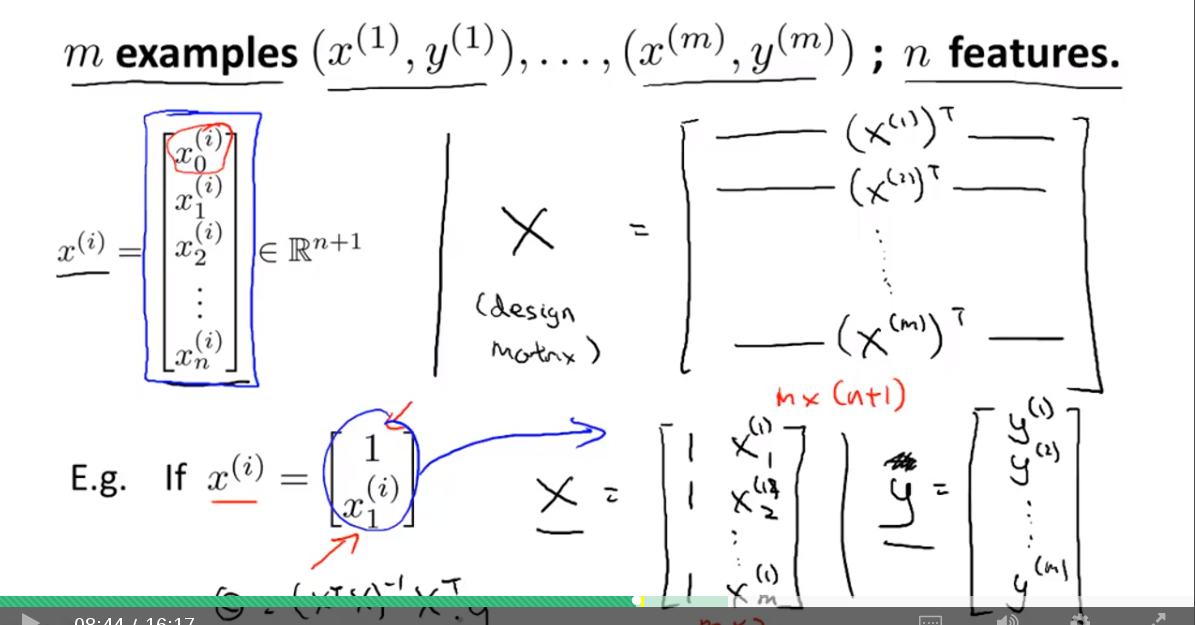
Idea:

X matrix design as follows:
N as features. And we have N + 1 features. i.e x0 = 1, due to mutiply with ϴ0.
M as number of samples.
x0 x1 x2 ... xN
R1
R2
R3
.
.
.
RM
Thus meaning:
ϴ[transpose]X = y[transpose]
or
X[transpose]ϴ = y
In order to have ϴ, we do:
ϴ = (X[transpose]X)^-1 X[transpose] y
- Find the inverse of Feature Square Matrix.X[transpose]X becomes a Feature Square Matrix [Feature]*[Feature].
- The inverse of Feature Square Matrix then times X[transpose]become a [Feature]*[Training Set] matrix.
- y is a [Training Set]*1 matrix.
- Thus ϴ is a [Feature] * 1 matrix.
[Training Set]*[Features]
So, the y is the matrix will be:
[Training Set]*1
So, the ϴ is the matrix will be:
[Features]*1
Octave for ϴ = (x[transpose]x)^-1 x[transpose] y:
# pinv(X'*X)*X'*y
Feature scaling:
While using normal equation methods, it's ok not to do feature scaling.
Reason? Because we are not using gradient descent method to find
the minimum value of J with ϴ.
So, which to choose? Gradient descent or Normal Equation?
m as training examples, n as features.
Gradient descent:
disadvantage:
Need to choose learing rate α.
Needs many iterations. ( By iterations means that with all the examples 'm',
we iterate with the same input of 'm' examples but with the tuning of ϴ)
Advantage:You run gradient descent for 15 iterations
Works well even n is large.
Normal equation:
Advantage:
No need to choose learning rate α.
Don't need to iterate.
disadvantage:
When n is large, computing (X[transpose]X)^-1 is HARD.
into computing O(n^3), which means SLOW.
While n >= 10000 , consider using gradient descent.

No comments:
Post a Comment
Note: Only a member of this blog may post a comment.