Reference:
Latency Numbers Every Programmer Should Know:
https://colin-scott.github.io/personal_website/research/interactive_latency.html



Latency Numbers Every Programmer Should Know:
https://colin-scott.github.io/personal_website/research/interactive_latency.html
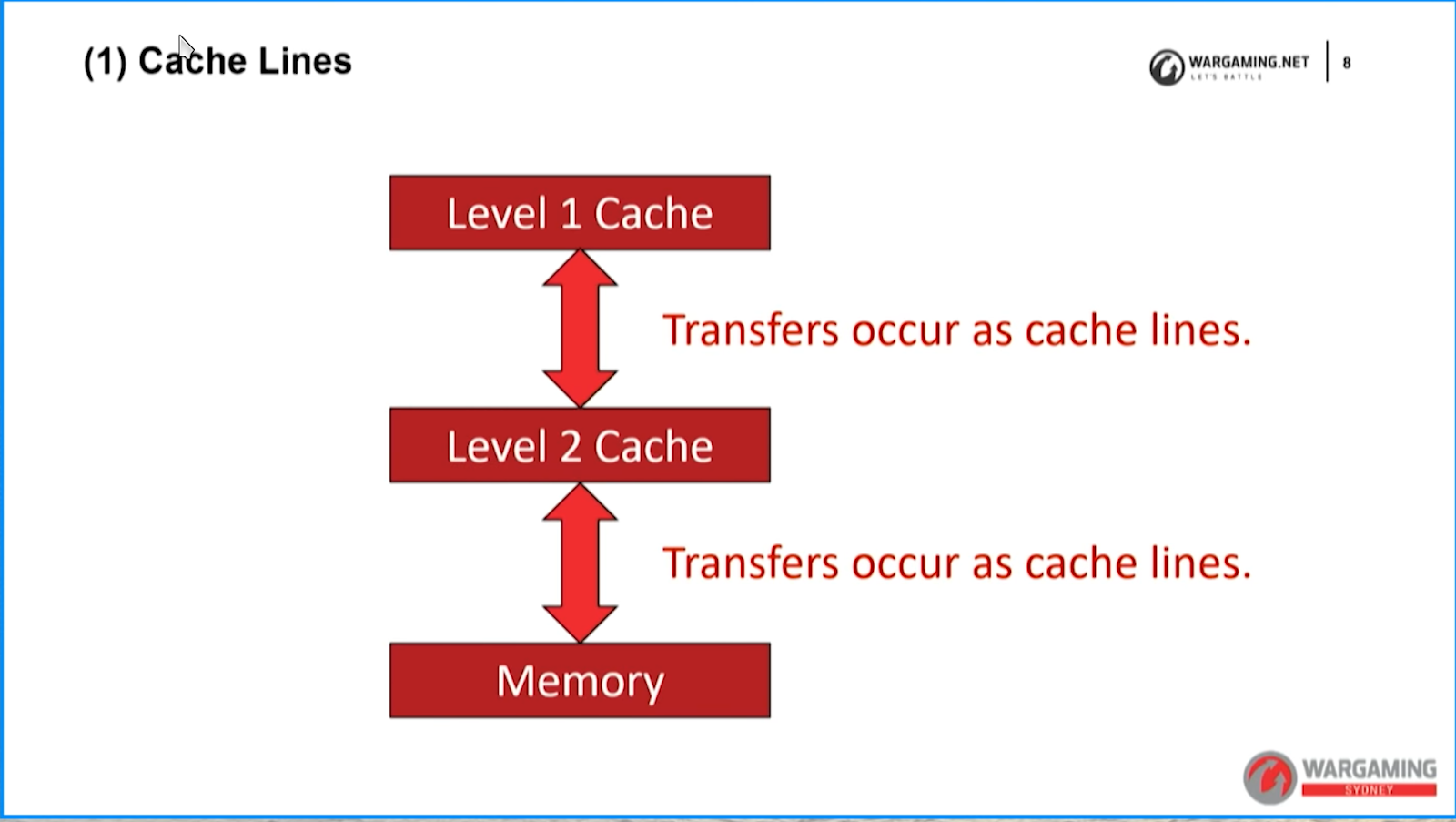
Cache Lines
- Compact data structure
- Padding
https://vsdmars.blogspot.com/2014/01/c-c-lost-art-of-c-structure-packing-by.html
http://vsdmars.blogspot.com/2018/09/golangc-padding.html - Honor access cache pattern (sequential, do not jumping) http://vsdmars.blogspot.com/2017/11/cppcon-2014-data-oriented-design-mike.html
https://vsdmars.blogspot.com/2018/11/cppcon-2018-oop-is-dead-long-live-data.html
https://vsdmars.blogspot.com/2018/11/cppcon-2016-high-performance-code-201.html
Hardware Prefetch
- Predictable access patterns are faster
- We want sequential locality
Access Locality
- Cache locality
- Spatial
- Temporal
- Beware the algorithm/data structure to use honors cache locality.
- Look beyond just big-O notation as constant-time costs can differ significantly.
- Large benefit in hitting faster cache levels.
- In C++, allocators matters. In Go(lang), the standard implement dealt with this problem.
- In Go(lang), use flat map instead of std map.
Multipe CPU Core Considerations
- MESI
http://vsdmars.blogspot.com/2018/09/concurrency-c-wrap-up-2018.html
http://vsdmars.blogspot.com/2019/06/c-c-concurrency-in-action-second.html - Take care to avoid data sharing problems.


Write Combined Memory
- Accumulate writes to flush as 64Bytes operations
- Partial buffer flush causes: (avoid this)
- Not writing all bytes convered by a buffer
- Writing too many streams at once
- Atomic read-modify-write operations
- Write Combined memory read causes:
- C++ bit fields
- Optimization
- Virtually always an accident (read the source code of implement)
- Solution: Expose write-only interface
- Non-temporal writes on x86:
Optimizing Cache Usage With Nontemporal Accesses - Use compiler intrinsics:
- SSE2
- _mm_stream_si32: store 4 bytes
- _mm_Stream_si128: store 16 bytes
- AVX
- _mm256_stream_si256: store 32 bytes
- AVX-512
- _mm512_stream_si512: store 64 bytes
Address Translation
- hugepage: https://vsdmars.blogspot.com/2019/12/hugepagekernelnotes.html#more
https://www.kernel.org/doc/html/latest/core-api/cachetlb.html
TLB flush optimization: https://lwn.net/Articles/684934/ - TLB size (4KiB pages)
- Intel Skylake Series:
- L1: 64 entries => 256 4KiB addressed
- L2 shared: 1536 entries => 6144KiB addressed
- Thus, use hugepage!
- Platform-specific
- Not directly pageable
- Difficult/slow to allocate
- Linux: Use hugepage
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.