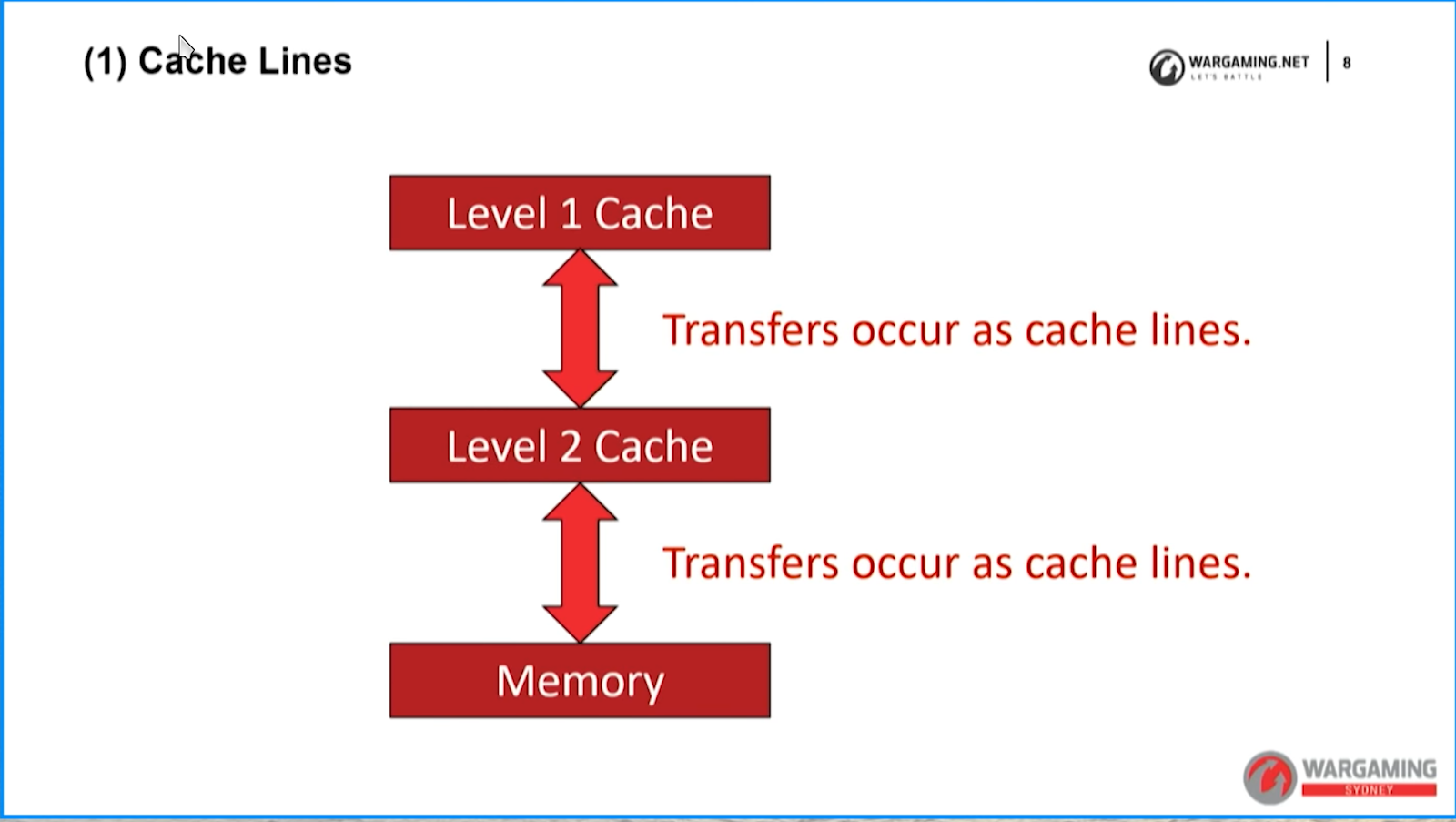
Reference:
https://dave.cheney.net/2016/08/20/solid-go-design
Bad code
Old fashion articles
- Rigid. Is the code rigid? Does it have a straight jacket of overbearing types and parameters, that making modification difficult?
- Fragile. Is the code fragile? Does the slightest change ripple through the code base causing untold havoc?
- Immobile. Is the code hard to refactor? Is it one keystroke away from an import loop?
- Complex. Is there code for the sake of having code, are things over-engineered?
- Verbose. Is it just exhausting to use the code? When you look at it, can you even tell what this code is trying to do?
SOLID
- Single Responsibility Principle
- A class should have one, and only one, reason to change.
- Coupling & Cohesion
- Package names, don't use name like 'common', 'util' which are too broad.
- Unix philosophy; small, sharp tools which combine to solve larger tasks.
- Open / Closed Principle
Software entities should be open for extension, but closed for modification. - Liskov Substitution Principle
- Two types are substitutable if they exhibit behaviour
- such that the caller is unable to tell the difference.
Require no more, promise no less. - Interface Segregation Principle
- Clients should not be forced to depend on methods they do not use.
- A great rule of thumb for Go is accept interfaces, return structs.
- Dependency Inversion Principle
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
- In Go, import graph must be acyclic.
- All things being equal the import graph of a well designed Go program should be a wide, and relatively flat, rather than tall and narrow.
- If you have a package whose functions cannot operate without enlisting the aid of another package,that is perhaps a sign that code is not well factored along package boundaries.
Focus
- Go programmers need to start talking less about frameworks, and start talking more about design.
- We need to stop focusing on performance at all cost, and focus instead on reuse at all costs.
- What I want to hear is people talking about how to design Go programs in a way that is well engineered, decoupled, reusable, and above all responsive to change.